
Docker: o básico para desenvolver projetos de Data Science - Parte 1
Introdução
Atualmente, Docker se tornou uma ferramenta essencial para computação moderna. Não importa sua posição em uma organização (data scientist, dev, etc), você precisa saber o básico de Docker! Como esse blog é voltado para área de machine learning/inteligência artificial, o foco desse post (que terá 2 partes), é introduzir o básico de Docker para desenvolver projetos na área. Não é intenção desse post:
- Discutir todos os conceitos do Docker ou algo do tipo
- Ser um guia definitivo para MLOps
- Definir tudo que envolve o Docker
É intenção desse post:
- Discutir os conceitos básicos para iniciar um projeto de ML no Docker
- Servir como um guia de bolso (cheat sheet) para situações básicas
Para mais informações sobre o Docker, você pode se direcionar a documentação oficial (em inglês), ou acessar o repositório do Github com bastante informação sobre a ferramenta.
O que é Docker?
De maneira geral, Docker é uma ferramenta utilizada para isolar a execução de processos dentro de um kernel Linux (atualmente existem ferramentas para emular Docker para Windows e Mac, mas originalmente foi proposto para Linux e é onde funciona melhor). A ferramenta trabalha com o conceito de imagens e containers, que tem funcionamento parecido com uma máquina virtual (mas definitivamente não é uma VM). Com o Docker acabou aquela história de: na minha máquina funciona. É possível replicar o ambiente de maneira exata dentro de um container sem afetar nada dentro da sua máquina de origem.
Imagens e containers
Para começar a entender o que é Docker, temos que entender como funciona a ideia de imagens e containers. Vamos fazer uma analogia com o sistema de orientação a objetos. Uma imagem é como uma classe que pode ser instanciada e o container é, obviamente, uma instância dessa classe. Dessa forma, imagine que temos uma imagem de um sevidor Node.js. Podemos criar diferentes instâncias a partir dessa imagem para diferentes propósitos. Essas instâncias serão os containers, que atuam de maneira isolada, ou seja, o que você faz dentro do container não afeta outro container ou seu Sistema Operacional (SO). Cada container tem seu próprio sistema de arquivos, que é gerado a partir de uma imagem. Você pode destruir todo ambiente dentro do container, se você tem a imagem que o gerou, você consegue replicar ele. Mas atenção: você replica o ambiente, arquivos são efêmeros! Vamos falar mais disso em breve.
Você pode ter vários containers, criados a partir de diferentes imagens, rodando no mesmo Kernel, como ilustrado na Figura 1. É importante saber que eles vão dividir recursos do kernel, mas é possível configurar a quantidade que cada um deles pode usar (por exemplo, restringir uso de memoria RAM).
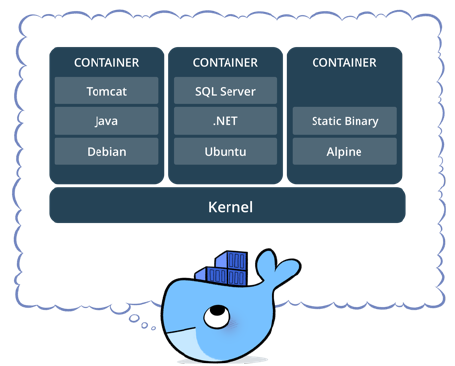
Existem diversas vantagens em utilizar o Docker. Sem entrar muito em detalhes, você vai ter modularidade das suas aplicações, fácil replicabilidade e instalação do ambiente, etc. Você pode subir uma aplicação em segundos. Em relação a VMs, eles são mais leves e permitem compartilhamento de recursos. Uma VM é bem mais pesada, mas é possível criar uma instância do Linux, por exemplo. No Docker, todas as imagens são baseadas em kernel do Linux.
O que eu preciso ter instalado?
Primeiramente, para instalar tudo que é necessário, você deve serguir o tutorial oficial da ferramenta de acordo com o seu sistema operacional. Básicamente é necessário:
- Ter a engine do Docker rodando na máquina host (que pode ser sua máquina, no caso)
- Instalar o Docker client para ter a API da ferramenta (que nada mais é do que os comandos a serem utilizados no bash)
- Criar um login em um Docker registry, que nada mais é do que um servidor na qual você pode baixar images. O maior registry público é o Docker hub. Lá você encontra imagens para, basicamente, qualquer serviço que você precisar.
Feito isso, você já está com acesso ao mundo Docker.
Ciclo de vida básico do docker
Se você já está habituado a utilizar o git na linha de comando, usar o Docker vai ser algo bem natural. A ideia é a mesma, você vai abrir o seu terminal, chamar o cliente e passar comandos para ele no padrão:
$ docker <opções> <comandos>
O primeiro comando que você deve encontrar em vários tutoriais é o run. Porém, ele é uma composição de vários comandos. Portanto, para ter uma visão geral, vamos começar do começo. E o começo é baixar uma imagem do docker hub. Acesse o site e crie uma conta. Você pode buscar a imagem que quiser, mas aqui vamos utilizar uma imagem do Ubuntu. Para baixar essa imagem, vamos utilizar o comando pull:
$ docker image pull ubuntu
Esse comando vai baixar a imagem do ubuntu para sua máquina. Isso pode levar alguns minutos, depende da sua internet. Uma vez que a imagem foi baixada, vai ser atribuido a ela uma tag e um ID. Para verificar, você deve usar o comando $ docker images, que lista todas as imagens que você tem disponível na sua máquina e vai te mostrar algo do tipo:
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest f643c72bc252 4 months ago 72.9MB
A partir dessa imagem podemos criar um container com o comando docker container create. Esse comando cria um container e também atribui um nome e um ID único. Porém, é sempre interessante dar nomear o container ao invés de deixar o nome aleatóreo, para isso, vamos utilizar a opção --name. Além disso, temos que passar mais dois parâmetros: o -i para criar um container interativo e deixar a entrada STDIN disponível quando subirmos o mesmo e o -t para criar um pseudo-terminal. Juntando tudo, temos:
$ docker container create -i -t --name meu_ubuntu ubuntu
Se tudo deu certo, o docker retorna o ID do container criado. Para listar todos containers criados, você pode utilizar o comando $ docker container ls -a. Por padrão o comando ls pede que o docker liste apenas os containers que estão sendo executados e opção -a indica que queremos listar todos (all) os container existentes, não apenas os que estão em execução. A saída desse comando retorna algo do tipo:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f42ba0e57b70 ubuntu "/bin/bash" 34 seconds ago Created meu_ubuntu
Um comando similar, seria o $ docker ps -a que tem o mesmo efeito.
Uma vez criado, podemos iniciar o nosso container. Para isso, utilizamos o comando start passando como parametro o ID ou nome do container. Como nomeamos o container como meu_ubuntu, vamos utilizar essa chave. Além disso, precisamos novamente usar o parâmetro -i e também o -a que fala para o docker anexar o STDOUT do container. Com isso, o comando completo fica: $ docker container start -i -a meu_ubuntu. Se tudo deu certo, vai aparecer o bash de um terminal com root para você:
$ root@67adc6b6fbb1:/#
Agora, tudo que você fizer dentro desse container estará isolado dentro da sua máquina. Por exemplo, se rodarmos o comando $apt-get install nano, ele vai instalar o Nano somente dentro do container.
Se você abrir outro terminal e rodar o comando $ docker container ls (ou ps) você vai ver que o container meu_ubuntu está com status up:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
67adc6b6fbb1 ubuntu "/bin/bash" 9 minutes ago Up 2 minutes meu_ubuntu
Isso indica que ele está rodando. Se você der um exit no terminal do seu container, esse status vai mudar para exit, mas lembre-se que é necessário usar o parametro -a no comando anterior para listar todos os containers, inclusive aqueles que não estão rodando no momento.
Outra maneira de parar um container em execução é através do comando stop. Em um outro terminal, você pode executar o seguinte comando: $ docker container stop meu_ubuntu. Ele vai parar de executar o container imediatamente. Isso é útil, principalmente, para containers rodando no background, mas a gente ainda vai chegar lá.
É importante saber
-
Um container que foi parado (ou stopado) apenas para de executar. Ele ainda existe no seu sistema e pode ser reiniciado utilizando o comando
start. Por isso existe a diferença em listar containers em execução e listar todos os containers. -
Para remover um container criado, podemos utilizar o comando
$ docker container rm <ID ou NOME>. Esse comando sim elimina o container. Como o comandolslista apenas os containers em execução, é comum usuários iniciantes acumular dezenas de containers. Isso pode ocupar bastante espaço no disco. Fique atento. -
Não confunda uma alterações feitas em um container com aquelas feitas nas imagens. Por exemplo, se você cria uma pasta dentro do container e depois apaga esse container, essa pasta não persiste na imagem. Qualquer outro container criado a partir da mesma imagem, não vai ter essa pasta. Isso é fonte de muita confusão entre os iniciantes em docker.
-
Você pode criar uma imagem nova a partir de um container. Vamos fazer isso mais para frente.
-
Como o container é isolado da sua máquina, os sistemas de arquivos são diferentes. Com isso, você não acessa os mesmos dados da sua máquina dentro do container. Ao menos que você use um
volume, que também vamos falar mais para frente.
Por fim, o docker possui uma sintaxe antiga e uma nova. Até a data deste post é possível usar as duas. Porém, você pode encontrar as seguintes formas:
docker image pull->docker pulldocker container create->docker createdocker container start->docker start
Perceba que a forma nova preza pela interpretabilidade e legibilidade do comando, ou seja, eu tenho que escrever um pouquinho a mais (incluir image ou container) para descrever onde o comando deve atuar. Podemos imaginar a forma antiga como um atalho.
O comando run
Agora que você entendeu o ciclo de vida básico de um container do docker, vamos ao comando run. De maneira geral, ele faz tudo que aprendemos até aqui, só que de uma vez só. Porém, é importante entender o ciclo antes de iniciar por ele (pelo menos na minha opinião). Então vamos criar um container a partir da imagem do debian. Eu quero que essa imagem se chame meu_debian e quero rodar um terminal dentro dela. Sendo assim, fazemos:
$ docker run -ti --name meu_debian debian /bin/bash
O comando vai fazer o seguinte:
- Se você não tiver a imagem baixada na sua máquina, ele vai baixar. Poranto, ele executa um
pull - Na sequência ele cria um container (comando
create) a partir dessa imagem e coloca o nomemeu_debian. Perceba que usamos o parâmetro-tijuntos, para criar um container interativo. Essa é apenas uma forma mais rápida de utilizar os dois - Por fim, ele vai da um
startno container que acabou de ser criado. Dentro desse container, nós pedimos para executar um terminal com o comando/bin/bash.
Se tudo deu certo, após executar o container, ele vai retornar o ID dele e vai te oferecer o prompt do bash, algo mais ou menos assim:
Unable to find image 'debian:latest' locally
latest: Pulling from library/debian
bd8f6a7501cc: Pull complete
Digest: sha256:ba4a437377a0c450ac9bb634c3754a17b1f814ce6fa3157c0dc9eef431b29d1f
Status: Downloaded newer image for debian:latest
root@4ad3a6f54e87:/#
Observe que você poderia executar qualquer outro comando dentro do container. Baseado no exemplo anterior, poderiamos fazer:
$ docker run -ti --name meu_debian2 debian bash "sleep 3; echo dormi 3s e acordei;"
O container meu_debian2 vai ser criado e iniciado, e executaria o comando passado, que é executar um sleep no bash e depois imprimir dormi 3s e acordei. Assim que finalizar a execução, o container para de executar.
Dica: se você quer subir um container para fazer uma operação (por exemplo, treinar um modelo) e na sequência apagar o mesmo (para não ficar acumulando na sua máquina), você pode usar o parâmetro --rm que faz exatamente isso. Por exemplo: $ docker run -ti --rm --name meu_debian debian /bin/bash. Assim que você sair ou parar esse container, ele vai ser excluído.
Rodando containers no background
Até o momento colocamos os containers para rodar apenas de maneira interativa. Mas imagine que você queira deixar rodando um servidor Jupyter, por exemplo. Não seria tão legal deixar ele rodando no terminal. Seria mais interessante deixá-lo no background e ter o terminal disponível para qualquer outra coisa. Isso é facilmente alcançado com o parâmetro -d, que vem de detach ou desacomplar. Vamos colocar um container de uma imagem do ubuntu rodando no background:
$ docker run -d -ti --name meu_ubuntu_back ubuntu /bin/bash
Se tudo deu certo, ele retorna o ID do container que acabou de criar e vai devolver o terminal da sua máquina! O container está rodando no background! Para verificar, vamos dar uma olhada com o $ docker ps:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3eb900793259 ubuntu "/bin/bash" 6 seconds ago Up 3 seconds meu_ubuntu_back
Como podemos ver, o nosso container está rodando no background! Podemos executar um comando qualquer nesse container utilizando o comando docker exec, por exemplo, vamos imprimir a variável PATH do meu container:
docker exec meu_ubuntu_back echo $PATH
Basicamente estamos pedindo para o docker executar o comando echo $PATH dentro do terminal do container meu_ubuntu_back que deixamos rodando no background. Se tudo der certo, você vai ver o conteúdo da variável PATH impressa no terminal da sua máquina e o container continuará rodando em brackground. Isso é particularmente útil para deixar um código treinando um algoritmo no background, sem a necessidade de vincular a execução no terminal.
Se por algum motivo você necessite de vincular o container com o seu terminal, você pode usar o comando $ docker attach meu_ubuntu_back. Agora, você tem acesso interativo ao seu container. Por fim, se você deseja parar a execução de um container rodando no background, utilize o comando stop, por exemplo: $ docker container stop meu_ubuntu_background.
Volumes, portas, e restrições
Como já mencionado, o container roda isolado da sua máquina com seu próprio sistema de arquivos e configurações de rede. Porém, é possível expor dados – que no universo do docker é chamado de volumes – e portas de redes. Além disso, é possível restringir o quanto de recurso, como memória e CPU, cada container pode utilizar.
Volumes
Para acessar dados da sua máquina dentro de um container, precisamos mapear um volume. Fazemos isso adicionando o parâmetro -v. Na sequência, precisamos informar o caminho fora e o caminho dentro do container. Por exemplo, imagine que queremos expor o diretório /home/user/dados da minha máquina host com um container construído a partir de uma imagem do Ubuntu. Portanto, temos que informar ao docker esse caminho e também onde, dentro do container, queremos acessar esse diretório. Vamos dizer vai ser dentro do /home/container/dados. Sendo assim, vamos criar o container com o volume mapeado:
$ docker run -ti -v /home/user/dados:/home/container/dados --name meu_ubuntu_vol ubuntu /bin/bash
Agora, usando o bash do container, você pode acessar todos os dados que estão mapeados no diretório informado. A principais vantagens são:
- Compartilhar dados entre a máquina host e o container
- Persistir dados, ou seja, tudo que você alterar dentro do diretório mapeado, também vai ser alterado na sua máquina
Você pode mapear apenas um arquivo, por exemplo, texto.txt. Além disso, também é possível mapear dados entre containers, mas esse assunto já foge do escopo do nosso tutorial, só saiba que é possível.
Portas
Assim como os volumes, podemos mapear portas de redes entre a máquina host e os containers (ou entre containers). A ideia é basicamente a mesma, mas com portas de rede. Para tal, temos que utilizar o comando -p de maneira similar, colocando a porta do host : porta do container. Então imagine a seguinte situação, vamos subir um servidor dentro do container (poderia ser um Jupyter notebook, mas vamos fazer isso na parte 2 desse post) e queremos acessar esse servidor a partir da máquina host. Para exemplificar de maneira simples, vamos utilizar uma imagem do nginx, que nada mais é do que um servidor HTTP. O servidor rodar no localhost:80, mas queremos acessar ele, na nossa máquina, utilizando localhost:8080. Para isso vamos utilizar o seguinte comando:
docker run -ti --rm -p 8080:80 nginx
Se tudo deu certo, o docker subiu um container, que por sua vez subiu o servidor na porta 80 que foi mapeada na porta 8080 da nossa máquina. Para acessar, basta abrir o seu navegar e digitar localhost:8080. Você vai ver a seguinte mensagem do servidor:
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and working. Further configuration is required.
For online documentation and support please refer to nginx.org.
Commercial support is available at nginx.com.
Thank you for using nginx.
Esse vai ser o mesmo princípio que vamos utilizar para subir nosso servidor Jupyter (cenas do próximo capítulo post).
Restricões
No Docker também é possível restringir o uso de recursos pelos containers. Isso é mais útil quando você tem vários containers rodando em um servidor, por exemplo. Todavia, acho interessante você saber que existe o recurso.
- Para restringir o uso de memória RAM, você pode usar o parâmetro
-mseguido da quantidade, por exemplo,500Mpara 500Mb. O comando completo seria:$ docker run -ti -m 500M --name meu_ubuntu_mem ubuntu /bin/bash - Para restringir núcleos de CPU, usamos o parametro
-cseguido da quantidade de núcleos, exemplo:$ docker run -ti -c 2 --name meu_ubuntu_cpu ubuntu /bin/bash - Se você possui uma GPU, você pode indicar o uso dela no container com o comando
--gpus. Nesse caso você pode usarallou um device específico. Vamos falar melhor disso no próximo post.
Existem diversas outras restrições que você pode atribuir ao seu container. Acredito que essas 3 já são mais do que suficientes para o nosso propósito.
Criando, salvando, e carregando images
Nessa última seção, vamos dar uma pincelada em como criar, salvar e carregar imagens. E para começar, vamos falar do Dockerfile.
Dockerfile
O Dockerfile nada mais é do que uma sequência de instruções bem estruturadas para criarmos uma imagem personalizada a partir de outra imagem. A partir dessa imagem, podemos subir um novo container, como mostrado na Figura 2.
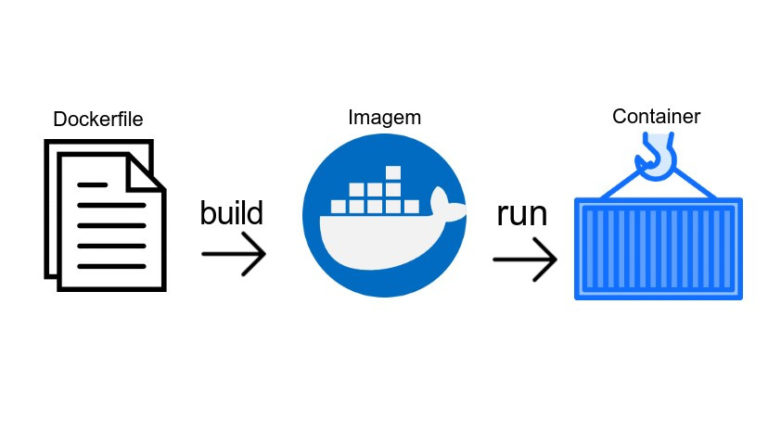
O primeiro passo é criar um arquivo chamado Dockerfile. Para escrever a receita da sua nova imagem, você precisa utilizar a sintaxe da ferramenta. Não é intenção desse post descrever toda a sintaxe, pretendo apenas ilustrar o básico. Nesse post, vamos ilustrar apenas dois comandos:
FROM: indica a imagem base para criarmos a nossa imagemRUN: roda um comando dentro dessa imagem
Na parte 2, vamos falar de alguns outros como o ADD, EXPOSE e VOLUME. Se você ficou curioso e quer saber mais, você pode checar aqui a descrição de uma gama de comandos.
Utilizando os dos comandos citados acima, vamos criar uma imagem baseada na imagem do Ubuntu, mas vamos instalar o Python nela. Vamos chamar essa imagem de Ubuntu_Python. No nosso arquivo Dockerfile, vamos escrever:
FROM ubuntu:latest
RUN apt-get install python3
Essa “receita” diz para o docker que a partir da imagem mais recente do Ubuntu queremos rodar o comando apt-get install python3 dentro dela para criar uma nova imagem. Para executar essa operação, temos que usar o seguinte comando:
$ docker build --name ubuntu_python ./
Esse comando vai buildar a nossa imagem, que estamos nomeando ubuntu_python, a partir do arquivo Dockerfile que se encontra no diretório ./. Quando a operação terminar, se você executar o comando $ docker images, você vai ver que na lista de imagens, agora você também possui a imagem ubuntu_python. Agora, sempre que você subir um container a partir dessa nova imagem que você acabou de criar, ele já vai ter o Python instalado, o que não ocorre na imagem do Ubuntu original.
Esse é um exemplo bem simples, que tem intuito apenas de conceituar e entender como funciona o Dockerfile. Porém, a ferramente é bem poderosa e você pode criar imagens com Python, Pytorch, TensorFlow, Sklear, etc e chamar ela de ml_python. Esse é o spoiler da parte 2 desse tutorial, na qual vamos fazer isso.
Dica: se você usa VScode, você pode baixar esse plugin para trabalhar com a sintaxe da ferramenta.
Comitando uma imagem
Também podemos criar uma imagem através do comando commit. A ideia é simples, imagine que queremos modificar nossa imagem ubuntu_python que acabamos de criar. Mas não queremos rodar um Dockerfile (como é exemplo é simples, não faz tanta diferença, mas para um Dockerfile grande que faz diversas operações, faz bastante diferença). O que a gente quer fazer é basicamente instalar o editor de texto Nano. Para isso, vamos fazer o seguinte. Vamos subir um container da nossa imagem e vamos executar um comando dentro dela, no caso o apt-get install nano. Nessa altura do campeonato, espero que você já saiba fazer essas operações, mas elas seriam:
$ docker run -ti -d --name ubuntu_python_cont ubuntu /bin/bash
$ docker exec ubuntu_python_cont apt-get install nano
Com isso, teremos os Nano instalado no container. Agora vamos comitar ele para criar uma nova imagem:
$ docker commit ubuntu_python_cont ubuntu_python_nano
O comando commit vai criar uma nova imagem, que nomeamos ubuntu_python_nano, a partir do container que subimos de ubuntu_python_cont, que é rodado a partir da imagem ubuntu_python. Se você entendeu essa frase perfeitamente, parabéns, você entendeu o ciclo de vida do docker. Se não, releia com cuidado e revisite as outras seções.
Por fim, você acabou de criar uma nova imagem!
Salvando e carregando imagens
Para concluir esse tutorial, vamos falar rapidamente de como salvar e carregar backups a partir de arquivos. Imagine que você queira salvar as suas imagens em um pendrive para carregá-las em algum outro lugar. Isso é fácilmente alcançado utilizando o comando save da seguinte maneira:
$ docker save -o minhas_imagens.zip <imagem_1> <imagem_2> ... <imagem_n>
O comando vai salvar uma ou mais imagens, que é/são especificada(s) no final, no arquivo minhas_imagens.zip. O parâmetro -o vem de output. Veja que de maneira simples, você fez um backup de um conjunto de imagens.
Para carregar essas imagens é igualmente simples, basta utilizar o comando load:
$ docker load -i minhas_imagens.zip
O comando vai carregar todas as imagens que estão dentro do .zip para dentro do docker. O parâmetro -i vem de input. De maneira simples, você consegue fazer backups das suas imagens.
Também é possível fazer o push de uma imagem para dentro de um docker registry, como o docker hub. Mas, novamente, apenas saiba que isso existe.
Considerações finais
Neste post introduzimos o básico que você precisa saber de docker para começar a utilizá-lo. É óbvio que existem mais uma infinidade de coisas, e sugiro que você dê uma olhada nos links destilados ao longo do post. Mas, com as informações discutidas aqui já é possível utilizar o docker para projetinhos de machine learning / data science. Na parte 2 desse post, vamos criar umas imagens específicas para ML e colocar para treinar um modelo.
Como sempre, caso tenha algum sugestão ou encontre alguma informação imprecisa neste post, não hesite em deixar um comentário.
Até a parte 2!
Deixe um comentário