
Introdução ao Scikit-learn - Parte 2: criando o primeiro projeto
Introdução
Esse é o segundo post da série de tutorias sobre a Scikit-learn. No primeiro post apresentamos uma visão geral da biblioteca e seus principais módulos. Sendo assim, temos uma ideia de como tudo funciona dentro dela. Porém, é comum ficarmos perdidos quando estamos aprendendo algo novo. Uma pergunta justa aqui seria: entendi os módulos principais, mas por onde eu começo?. Acredito que a primeira reposta para essa pergunta seja: pelos dados! Ora, a sklearn é uma biblioteca voltada para machine learning, que por sua vez, não existe sem dados!
Essa é uma resposta correta. Mas também temos que entender qual problema queremos solucionar, quais métodos podemos utilizar, como a biblioteca pode nos ajudar, etc. Sendo assim, a intenção desse post é mostrar os caminhos oferecidos pela biblioteca bem como solucionar nosso primeiro problema com ela. A ideia é iniciar um projeto de maneira simples e ir melhorando nossa solução nas partes subsequentes.
Novamente, esse série é um recorte do que a biblioteca pode fazer.
Por onde começar?
De acordo com a documentação oficial, a sklearn oferece algoritmos para lidar com 4 tipos principais de problemas na área de machine learning:
Além desses 4 tipos, podemos também considerar o pré-processamento e a seleção de modelos como “problemas colaterais” dos 4 principais.
Além disso, a biblioteca oferece um fluxograma para auxiliar na escolha de qual estimador utilizar para um dado problema.

De maneira geral, o caminho que a sklearn sugere depende principalmente do tipo do problema, da natureza e quantidade de dados. Obviamente, quanto mais experiência adquirimos na área, melhor é nossa percepção e escolha das melhores metodologias. Todavia, esse fluxograma é uma sugestão de caminho.
De qualquer forma, como o caminho depende dos dados, vamos escolher um problema e trabalhar os conceitos nele.
Datasets dentro da sklearn
Antes de colocar a mão na massa mesmo, vamos dar uma olhada no subpacote sklearn.datasets.
Como já vimos, os algoritmos implementados dentro da sklearn consomem os dados em forma de array-like. Portanto, você poderia carregar-los utilizando qualquer biblioteca de manipulação de dados disponível no universo do Python. Todavia, para facilitar o aprendizado a biblioteca oferece o subpacote sklearn.datasets que nada mais é do que uma coleção de funções para carregar dados já conhecidos da comunidade. Além disso, ela oferece maneiras de produzirmos dados fictícios aleatórios para um dado problema (isso serve apenas para fins de aprendizagem e teste). Por exemplo, podemos criar um problema de classificação que possui 200 amostras, 10 atributos e 2 classes da seguinte forma:
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=200, n_features=10, n_classes=2)
Com isso, poderiamos testar se um modelo ou pipeline está funcionando ou algo do tipo.
Existe uma lista de datasets reais que podem ser obtidos através da API da biblioteca. Apenas para exemplificar, vamos carregar o famoso dataset das Iris:
from sklearn.datasets import load_iris
iris_dataset = load_iris()
X = iris_dataset['data']
y = iris_dataset['target']
descricao = iris_dataset['DESCR']
De maneira padrão, as funções que carregam os dados retornam um dicionário com informações do dataset e os dados propriamente ditos. Porém, você pode alterar para retornar apenas os dados. Como você sabe disso? checando a documentação exata da função.
Nota 1: se você solicita o dataset pela primeira vez ele vai baixar os dados (para os datasets maiores).
Nota 2: você pode brincar de criar ou carregar datasets usando este Jupyter notebook que está no repositório do Github deste tutorial.
Iniciando nosso projeto
Sem mais delongas, vamos iniciar o primeiro projetinho. E para começarmos de maneira mais simples, vamos classificar a famosa base de dados de wine. E de maneira totalmente supreendente (ou não) ela está na API da sklearn.datasets.
Base de dados wine
Primeiramente, vamos carregar a base:
from sklearn.datasets import load_wine
wine_dataset = load_wine()
X = wine_dataset['data']
y = wine_dataset['target']
descricao = wine_dataset['DESCR']
print(descricao)
Ao imprimir a descrição, temos a informação de que a base possui apenas 178 amostras de vinhos, 11 atributos descrevendo características quimicas e coloração da amostra, e 3 classes diferentes. Outra informação relevante é que a base é de certa forma balanceada com cada classe possuindo 59, 71 e 48 amostras cada. Então, o problema a se solucionar é de certa forma simples: dado uma amostra de vinho que possui 11 atributos, qual a classe que esse vinho pertence?
Obviamente, em uma situação real é necessário estudar esses atributos. Se possível, com especialistas no assunto. Como estamos apenas aprendendo a trabalhar com a biblioteca e eu não entendo absolutamente nada de vinho, não vamos explorar essa parte. Mas tenha em mente que analisar e selecionar os atributos é importante.
Escolhendo um classificador
A sklearn disponibiliza vários algoritmos de classificação, dentre eles: rede neural, SVM, árvore de decisão, KNN, regressão logistica, etc. Você pode encontrar vários deles nesta lista. Como esse é um problema simples, vamos solucioná-lo utilizando o KNN (K-nearest neighbours), para os mais íntimos, K-vizinhos mais próximos.
Nota: caso você não conheça o KNN, clique aqui para acessar o post deste blog em que o algoritmo é descrito.
O KNN dentro da sklearn é chamado de KNeighborsClassifier e fica dentro do subpacote sklearn.neighbors:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(...)
A documentação completa do modelo é descrita aqui. Nela podemos observar que o mesmo possui diversos parâmetros de configuração, como o número de vizinhos, o algoritmo utilizado para encontrar os vizinhos, a métrica de distância, dentre várias outras. Como já disse, a biblioteca é muito grande e permite bastante configuração. Normalmente, quando pretendemos solucionar um problema real, vamos precisar alterar esses parâmetros para fazermos uma busca. Porém, caso você não queira configurar nada (o que quase sempre não é uma boa, principalmente para algoritmos mais complexos), você pode deixar tudo com os parâmetros default que o método vai funcionar.
Planejando o mini-projeto
Agora que definimos o dataset e o algoritmo de classificação, vamos planejar o passo a passo do nosso projeto. Basicamente, o que precisamos fazer se resume a:
- Carregar os dados
- Pré-processamento
- Dividir o dataset em treino e teste
- Normalizar os dados
- Criar o classificador
- Configurar os parâmetros
- Realizar o treinamento
- Avaliar as métricas do modelo
Na seção base de dados wine nós já discutimos sobre como carregar a base de dados. Logo, vamos abordar os demais tópicos na sequência. Lembre-se que toda implementação se encontra no repositório do Github.
Aviso: daqui pra frente, sempre que você encontrar uma função nova e quiser entender completamente seus parâmetros e uso, você deve dar uma olhada a documentação oficial. Como já falamos aqui, a documentação é excelente e todas as funções e métodos tem descrição própria. Se você jogar no Google, por exemplo, sklearn.model_selection.train_test_split, ele vai te direcionar para a descrição dessa função exata.
Pré-processamento
Particionando o dataset
Nesta etapa, vamos dividir o dataset em duas partes: uma para treino e outra para teste. Isso é feito de maneira simples utilizando a função sklearn.model_selection.train_test_split:
from sklearn.model_selection import train_test_split
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=32)
Existem vários parâmetros para essa função, alguns obrigatórios e outros opcionais. Os obrigatórios são os conjuntos de dados X e y, que são os dados que serão divididos para as partições. Os demais parâmetros solicitam o seguinte:
test_size = 0.3: separar 30% dos dados para teste. Obviamente, 70% será para treino. Você poderia solicitartrain_size = 0.7que daria na mesma. Além disso, tenha em mente que esse valor pode não ser exato pois depende do tamanho da base (que é um número inteiro).shuffle = True: embaralhar a base antes de dividir os dados em partições.random_state = 32: faça com que o fator de aleatoriadade seja 32. Em outras palavras, vai setar oseedda função aleatória. Em termos prático, isso é importante para reproducibilidade. Sempre que você rodar essa função, mesmo com oshuffle = True, ele vai retornar a mesma partição referente ao valor passado para orandom_state. Se você remover esse parâmetro, toda execução gera uma partição diferente. Não existe certo ou errado, depende do que você quer fazer. No próximo post, por exemplo, vamos desejar que seja sempre aleatório.
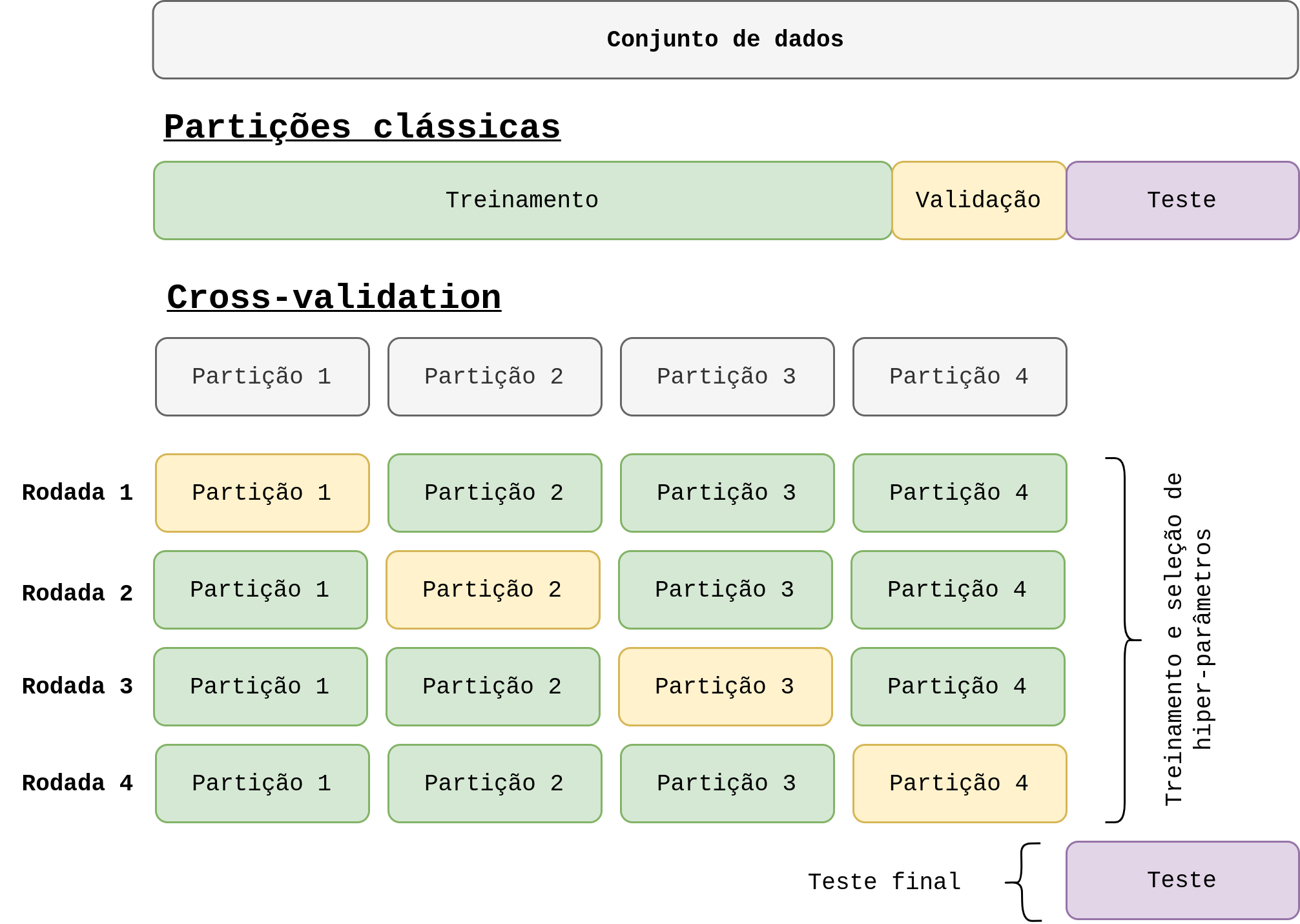
Nota: um maneira mais adequada para treinar e avaliar a qualidade de um modelo seria utilizando cross-validation. Isso será tema da parte 3 desse tutorial.
Normalizando os dados
Já falamos sobre normalização no post anterior. A ideia é basicamente a mesma aqui. Vamos utilizar o normalizador sklearn.preprocessing.MinMaxScaler que simplesmente utiliza o mínimo e o máximo de cada atributo para normalizar seus dados, não tem muito segredo.
from sklearn.preprocessing import MinMaxScaler
normalizador = MinMaxScaler()
normalizador.fit(X_treino)
X_treino_norm = normalizador.transform(X_treino)
X_teste_norm = normalizador.transform(X_teste)
Criando o classificador
Também já falamos sobre o classificador a ser utilizado na seção Escolhendo um classificador, que será o KNN. A princípio vamos utilizar o número de vizinhos igual a 3 (n_neighbors=3) e treinar o classificador:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_treino_norm, y_treino)
print(f"Acurácia de treinamento: {knn.score(X_treino_norm, y_treino)}")
Podemos explorar alguns métodos do estimador da seguinte forma:
y_pred = knn.predict(X_teste_norm)
y_pred_prob = knn.predict_proba(X_teste_norm)
acc_teste = knn.score(X_teste_norm, y_teste)
O método predict(), como já discutimos, retorna a classe predita para todas as amostras em X_teste_norm. Já o método predict_proba() funciona da mesma maneira, porém, ao invés de retornar a classe escolhida pelo classificador, ele retorna retorna a probabilidade atribuida a cada uma delas. Obviamente, a quantidade de probabilidades retornadas vai depender do número de classes. Para o nosso dataset, o método retornaria 3 probabilidades por amostra, uma vez que temos 3 classes.
Por fim, o método score() recebe os dados de entrada ou saída, não importa a partição, e retorna a acurácia do mesmo.
Dicas para poupar o seu tempo
Existem algumas observações/dicas importantes que pode te poupar um tempo tentando resolver erros bobos quando você está iniciando com a biblioteca. Por isso, acho válido compartilhar aqui:
- Os métodos
predict(),predict_proba(),score(), e qualquer outro método de estimadores que visa usar o modelo treinado, exigem que você execute o métodofit()primeiro. Se você tentar rodar alguns desses métodos antes de treinar o modelo com ofit(), a excessãoNotFittedErroré disparada. Em outras palavras, você está pedindo o modelo para ser executado mas ele não está treinado para tal. - Toda vez que o método
fit()é executado ele treina o modelo e seta os pesos. Se você possui um modelo treinado e executa esse método, ele será retreinado e os pesos do mesmo serão sobrepostos. - Como discutimos no primeiro post, o padrão dos dados de entrada
Xdeve ser um array-like na qual as linhas são as amostras e as colunas os atributos. Em termos de codificação, esse array sempre terá um shape(n_amostra, n_atributos). Sendo assim, o métodos dos estimadores sempre esperam esse padrão. Utilizando opredict()como exemplo, ele realiza a predição de uma ou mais amostras. Porém, se você quiser obter o resultado de apenas uma amostra, você precisa passar um array com shape(1, n_atributos). Em outras palavras, você não pode passar uma lista de atributos apenas pois o método vai retornar um erro, pois espera um padrão diferente. Para o nosso problema, para obter a predição de uma amostra apenas, você precisaria fazer o seguinte:amostra = normalizador.transform([[1,2,3,4,5,6,7,8,9,10,11]]) y_amostra = knn.predict(amostra)Perceba que o array amostra possui shape
(1, 11). - O método
score()retorna a acurácia porque estamos tratando um problema de classificação. Como a biblioteca segue o mesmo padrão para todos os estimadores, se este fosse um problema de regressão, por exemplo, o método retornaria um erro de estimação (como erro médio quadrático, por exemplo). Por isso sempre precisamos checar a documentação antes de utilizar os métodos. - Observe que para obter os resultados dos métodos de maneira correta é necessário utilizar a versão normalizada dos dados de entrada
X_teste_norm. Como treinamos o modelo com a normalização, se você passar os dados sem normalizar os resultado retornado estará incorreto, uma vez que o modelo não vai reconhecer a geometria espacial dos dados. Isso pode ser simplificado utilizando umPipeline, que vamos fazer na seção Utilizando um Pipeline.
Avaliação do modelo
O último passo do nosso pipeline é avaliar o modelo. Como já sabemos, a sklearn possui o módulo sklearn.metrics para executar tal tarefa. Aqui vamos utilizar duas funções muito úteis a classification_report e a confusion_matrix:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
relatorio = classification_report(y_teste, y_pred, target_names=nome_das_classes)
print("Relatório de classificação:")
print(relatorio)
mat_conf = confusion_matrix(y_teste, y_pred)
print("Matriz de confusão:")
print(mat_conf)
A classification_report retorna um relatório com várias métricas como precision, recall, F1-score, etc. Por sua vez, a confusion_matrix, como o próprio nome sugere, retorna a matriz de confusão do classificador. Minha sugestão aqui é executar o jupyter notebook disponibilizado no repositório do Github para verificar os retornos dessas funções.
Info: se você não entende essas métricas de classificação, dê uma olhada no post Medida de desempenho de classificadores para entender o que cada uma delas significa.
Utilizando um Pipeline
Como mostramos no post anterior, podemos simplificar algumas partes do nosso projeto utilizando um Pipeline. Para isso, fazemos:
from sklearn.pipeline import Pipeline
knn_pipeline = Pipeline(steps=[
("normalizacao", MinMaxScaler()),
("KNN", KNeighborsClassifier(n_neighbors=3))
])
knn_pipeline.fit(X_treino, y_treino)
y_pred = knn_pipeline.predict(X_teste)
y_pred_prob = knn_pipeline.predict_proba(X_teste)
print(f"Acurácia de treinamento: {knn_pipeline.score(X_treino, y_treino)}")
Depois de empacotato, utilizamos o knn_pipeline como qualquer outro estimador da biblioteca. Porém, observe que ao chamar as funções predict(), predict_proba() e score(), nós passamos os dados sem normalizar (X_teste, por exemplo). Isso ocorre por que agora o normalizador faz parte do nosso pipeline. Sempre que um dado entra nele, o primeiro passo é a normalização.
Buscando o número de vizinhos
Um parâmetro fundamental do KNN é o número de vizinhos, definido por n_neighbors. Até o momento, executamos o modelo com n_neighbors=3. Mas vamos fazer uma busca com o GridSearchCV, que já mostramos no post anterior.
from sklearn.pipeline import Pipeline
param_busca={
'KNN__n_neighbors': [3, 5, 7]
}
buscador = GridSearchCV(knn_pipeline, param_grid=param_busca)
buscador.fit(X, y)
print("Melhor K:", buscador.best_params_)
Como já falamos, o GridSearchCV faz uma busca exaustiva a partir dos parâmetros definidos no dicionário param_busca utilizando cross-validation. Observe que o parâmetro que passamos foi KNN__n_neighbors e não n_neighbors. Isso acontece porque estamos utilizando um Pipeline, que adiciona esse pré-fixo no parâmetro do estimador. Portanto é importante prestar atenção nessa parte para não acontecer algum erro bobo.
Por fim, para ter um relatório completo da execução do método, você pode dar uma olhada no atributo cv_results_, que retorna um dicionário contendo os resultados de cada execução. Se você tiver familiaridade com o Pandas, você pode construir um DataFrame e imprimir o resultado como tal ou até mesmo salver um arquivo .csv para avaliar melhor os resultados.
import pandas as pd
df = pd.DataFrame.from_dict(buscador.cv_results_)
print(df)
df.to_csv("relatorio.csv", index=False)
Salvando e carregado o modelo
Uma vez que o modelo foi treinado uma necessidade comum é salvá-lo no disco para ser reutilizado em alguma outra situação. A documentação oficial da ferramenta aponta duas bibliotecas do Python que são utilizadas para persistir dados em geral: a Pickle e a Joblib. Ambas podem ser utilizadas de maneira bem simples e funcionam bem. Porém, a documentação recomanda o uso da joblib pois ela mais é mais eficiente em carregar arrays com muitos dados, que é o caso da maioria dos modelos treinados com a biblioteca. Dessa forma, seguindo a recomendação, vamos salvar nosso modelo empacotado dentro do Pipeline anterior:
import joblib
joblib.dump(knn_pipeline, 'knn_pipeline.joblib')
Com isso o arquivo knn_pipeline.joblib será salvo no diretório atual. Você pode colocar qualquer diretório de sua preferência. Para carregar, também é bem simples:
knn_pipeline_carregado = joblib.load('knn_pipeline.joblib')
y_pred_prob = knn_pipeline_carregado.predict_proba(X_teste)
print(f"Acurácia de treinamento: {knn_pipeline_carregado.score(X_treino, y_treino)}")
Perceba que uma vez carregado, você pode exercutar o modelo da mesma forma que fazia antes de salvá-lo.
Considerações finais
Nesta parte do tutorial criamos um mini-projeto bem simples para classificar uma base dados bem fácil. A intenção era que fosse algo mais simples, apenas para introduzir as nunces da biblioteca de maneira bem detalhada. É interessante que você acesse o código no repositório e execute o mesmo alterando parâmetros e modificando os métodos para que você ganhe familiaridade com a biblioteca. Na próxima parte a intenção é analisar mais a fundo alguns pontos desse projeto e utilizar cross-validation para calcular as métricas do modelo.
Deixe um comentário