
Avaliação de modelos, cross-validation e data leakage
Introdução
Uma das primeiras lições que qualquer iniciante na área de machine learning aprende é que não devemos treinar e testar um modelo usando o mesmo conjunto de dados. Isso é um erro grave (e básico) que torna o modelo basicamente inútil. Ele pode, por exemplo, aprender a decorar exatamente as amostras para retornar uma métrica de avaliação alta e te iludindo que o treinamento foi feito com sucesso. Como você já deve saber, essa situação é conhecida como overfitting. Em problemas de aprendizado supervisionado, uma técnica comum para prevenir o problema é utilizando partições diferentes de treino e teste. Porém, ainda existe alguns fatores (que vamos discutir aqui) que faz com que essa abordagem não seja a melhor possível. Daí que surge a técnica de cross-validation (ou validação cruzada).
Embora o problema anterior gere o famigerado overfitting, ele não é a única causa do mesmo. Outro fator comum que também nos leva ao overfitting e o vazamento de dados entre as partições de treino e teste. Esse problema é conhecido como data leakage.
Neste post, vamos abordar esses dois temas principais. Primeiro, vamos discutir os conceitos básicos e boas práticas sobre cross-validation. Na sequência, vamos dar uma olhada no problema de data leakage e como se proteger dele.
Particionando o conjunto de dados
Antes de definirmos o que é e como funciona o cross-validation, vamos revisar o pipeline clássico de treinamento de modelos supervisionados.
A primeira técnica que aprendemos ao treinar um modelo é dividir os dados em treino e teste. Então, considerando um conjunto de dados X é comum dividí-lo em X_treino e X_teste, normalmente com 70% e 30% dos dados, respectivamente. Essa simples prática já é capaz de prevenir o overfitting de um modelo. Porém, temos um outro problema. Modelos possuiem hiper-parâmetros que normalmente são definidos de maneira empírica, ou seja, utilizando os próprios dados.
Dica: se você não sabe o que é um hiper-parâmetro, de um passo para trás e veja nosso post sobre conceitos básicos de machine learning.
Ao ajustar os hiper-parâmetros usando a partição de treino, ainda corremos o risco de obtermos um overfitting na partição de teste. Acontece que o processo de ajuste pode vazar informações (e dai vem o nome data leakage, que vamos tratar melhor ao decorrer deste post) do conjunto de teste para o modelo. Em outras palavras, alterar algum parâmetro pode fazer com que o desempenho no conjunto de teste melhore de maneira artificial, ou seja, não reflete a realidade e prejudica a generalização do modelo. Uma solução viável para esse problema é a criação de uma nova partição chamada de validação. Nesse caso, como o próprio nome sugere, a validação do modelo seria feita nessa partição e o teste final (como se fosse o mundo real) na partição de teste. Uma ilustração dessas partições clássicas é apresentada na Figura 1.
O grande problema agora é que a gente reduz o número de amostras na partição de treino e isso quase sempre é ruim uma vez que modelos de machine learning são data-greedy, ou seja, quanto mais dados melhor. Outro ponto interessante é que as partições ficam expostas a aleatoriedade. Em outras palavras, o modelo pode performar muito bem em uma determinada escolha de partição, mas muito mal em outra. Daí surge a necessidade do cross-validation.
Cross-validation (CV)
A ideia por trás do cross-validation é simples, porém muito efetiva. De maneira geral, ele nada mais é do que um procedimento na qual os dados são organizados. Como uma imagem vale mais do que mil palavras, vamos primeiro dar uma olhada na Figura 1 para termos uma ideia geral da técnica.
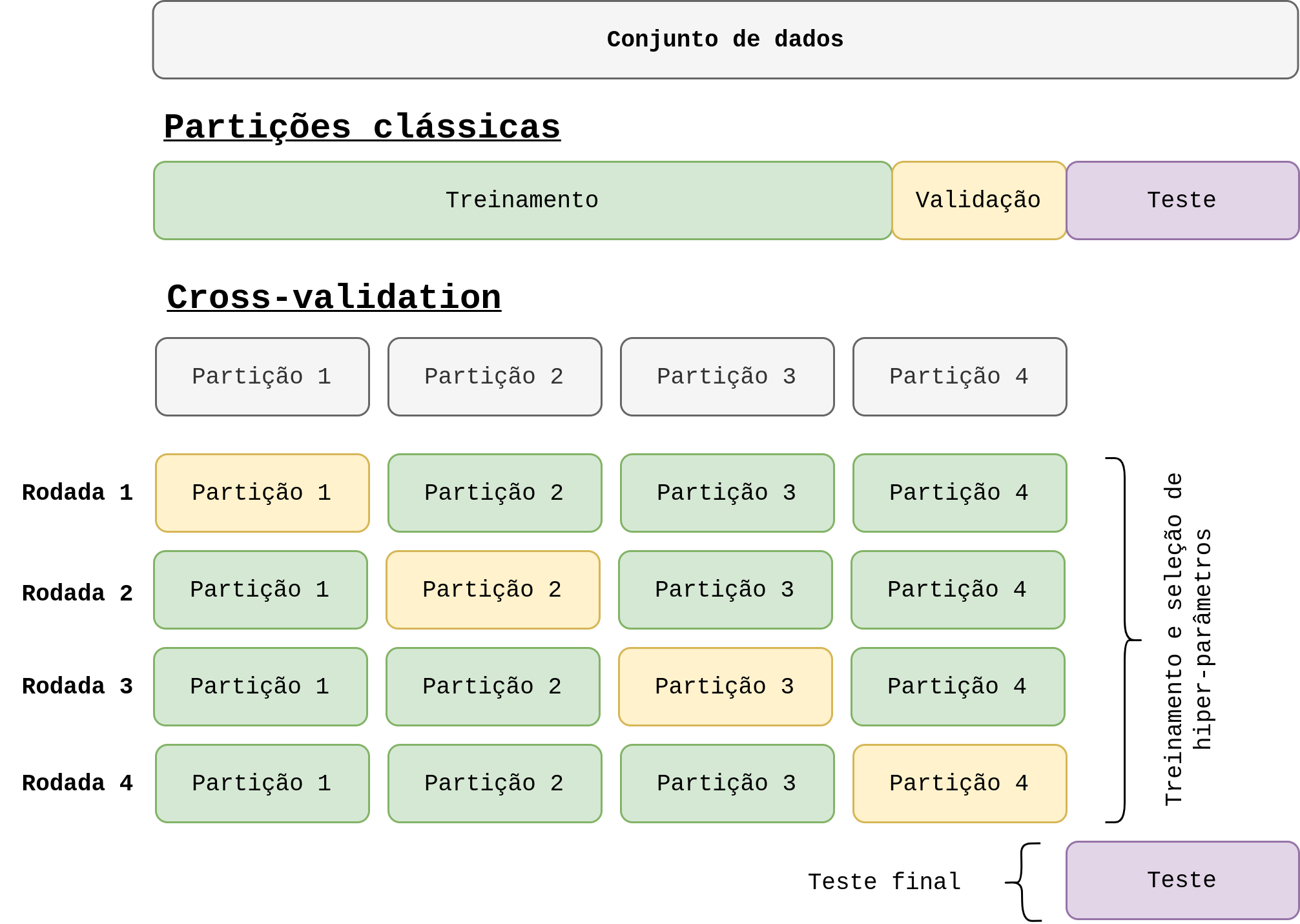
Como podemos observar, os dados são divididos em partições (no inglês conhecido como folders). Idealmente, cada partição deve conter a mesma quantidade de dados. Porém, isso depende do dataset e a maneira de dividir os dados. No final das contas, podemos ter uma variação pequena entre as partições (por exemplo, 25% em uma e 26% em outra). O número de partições é um parâmetro que devemos definir de ante-mão conhecido como k. Na Figura 1 esse valor é definido como k=4 e por conta disso, seria denominado 4-fold cross-validation.
O ponto central do CV é rotacionar as partições de treino e teste. A cada rodada, o modelo é treinado com k-1 partições e testado com uma. Na figura, isso é representado pelas cores verde e amarelo. Observe também, que existe um conjunto de teste final (em roxo) que é uma maneira de representar o desempenho do nosso modelo no mundo real. Dessa forma, o treinamento e a validação é realizado k vezes. Por fim, é feito a média da performance obtida em cada rodada para representar o desempenho geral do nosso modelo.
Como podemos observar, essa abordagem demanda mais processamento e mais tempo. Porém, é uma maneira bem prática para termos uma noção real do desempenho do nosso modelo. Além disso, ela “desperdiça” menos dados na partição de validação, uma vez que o modelo vai ser treinado usando todas as partições.
Determinando as partições
A maneira mais simples de determinar cada uma das partições ilustradas na Figura 1 é de maneira aleatória. Portanto, todos os dados seriam embaralhados e, de maneira aleatoria, seria selecionar uma % para teste e o restante seria divido em k partições. Essa abordagem funciona, mas para base de dados desbalanceadas pode não ser tão efetivo. Além disso, as vezes é interessante garantir que algumas regras sejam seguidas na divisão, o que nos leva a estratificação dos dados.
A estratificação pode ser feita por classe, grupos, ou ambos. A primeira é simples, se eu tenho um problema com 3 classes e que a classe 1 possui 80% dos dados e a 2 e 3 possuem 10 cada, é interessante estratificar as partições por classe. Em outras palavras, vamos garantir que cada partição tenha uma divisão das classes aproximada da original (80%, 10% e 10%). A estratificação por grupo depende muito do problema. Por exemplo, imagine que temos um problema de classificação de alguma doença a partir de uma imagem. E temos mais de uma imagem por pessoa. Colocar a mesma pessoa em partições diferentes contribui para vazar informação para o modelo. Dessa maneira, a estratificação visa garantir que imagens da mesma pessoa fique sempre na mesma partição. Por fim, a estratificação pode considerar tanto as classes quanto os grupos. É sempre bom lembrar, que a estratificação faz com que as partições possam ser ligeiramente diferente em termos de número de amostras, como já falamos anteriormente.
Data leakage
Ao longo desse post já falamos um pouco sobre data leakage, mas dada a sua importância e sua relevância, vamos dar um pouco mais de atenção.
Como já mencionamos, o termo leakage (vazamento) é usado para ilustrar o vazamento de dados de uma partição para outra. De maneira geral, esse problema vai ocorrer quando informações relevantes são obtidas pelo modelo enquanto ele está sendo desenvolvido, porém, quando o mesmo for colocado em produção ele não possui essa informação. Isso vai fazer que o modelo performe super durante a etapa de desenvolvimento, mas muito mal em produção.
Existem dois tipos principais [2]: target leakage e contaminação das partições de treino e teste.
Target leakage
Esse tipo de vazamento ocorre quando o modelo é treinado com algum dado que não vai estar disponível ou não contém o mesmo tipo de informação na fase de teste no mundo real. Por exemplo, imagine que o modelo deve classificar se uma pessoa teve pneumonia ou não. Um dos atributos será tomou_antibiotico. Esse atributo é problematico porque pessoas tomam remédio quando elas já possuem algo mais grave. Portanto, esse atributo vai estar relacionado, quase que na totaliade, com pessoas que tiveram pneumonia. Dessa forma, o modelo vai aprender, de maneira errada, que quem tomou antibiótico, teve pneumonia. ]
Provavelmente, a acurácia dos conjuntos de treino e teste serão ótimas. Mas quando o modelo for colocado com dados do mundo real, ele vai performar mal, uma vez que muitas pessoas vão ter pneumonia sem ter tomado o remédio. Perceba, que o dado estará disponível no mundo real, mas não da maneira que foi no treinamento.
Imagine a situação, você chega no hospital se queixando de dores no peito. Você ainda não tomou nenhum antibiótico, então a resposta para esse atributo será não. Sendo assim, o modelo vai atuar e retornar que você não possui pneumonia, mesmo com possibilidade de ser.
Prevenção
A única maneira de prevenir desse tipo de vazamento é removendo esse atributo na fase de pré-processamento dos dados. Por isso essa etapa é tão importante.
Contaminação das partições de treino e teste
Esse tipo de vazamento é o que apresentamos anteriormente quando falamos sobre o problema em que pode ter imagem da mesma pessoa em partições diferentes. Isso contamina as partições que por sua vez atrapalha o treinamento adequado do modelo uma vez que o mesmo obtém informações privilegiadas que ele não vai possuir no mundo real. Portanto, ao vazer informação do treino para o teste, a acurácia obtida nessa última partição pode não refletir a realidade.
Uma outra maneira contaminar as partições é normalizando todo o conjunto de dados antes de dividir as partições. Pode não parecer, mas ao fazer isso, você passa informações relevantes para o modelo sobre os dados de teste. Por exemplo, se você normaliza todos os dados utilizando o valor máximo dos atributos e utiliza o conjunto de teste para tal, você já o contaminou.
Prevenção
Como esse vazamento pode ocorrer de duas formas, precisamos tomar duas medidas de prevenção, uma simples e outra mais trabalhosa.
A medida simples é nunca utilizar qualquer tipo de fitting utilizando o conjunto de teste. Por exemplo, se vamos normalizar os dados utilizando o valor máximo de cada atributo, esse valores devem ser obtidos apenas no conjunto de treino. Com eles em mãos, normalizamos os dados de teste.
A medida mais trabalhaso envolve analisar e pré-processar os dados antes de iniciar a modelagem. No exemplo de fotos da mesma pessoa, a unica solução é conseguir identificar e agrupar esses dados. Porém, perceba que essa tarefa pode não ser fácil de ser executada.
Considerações finais
Neste post discutimos dois conceitos importantíssimos para treinamento e avaliação de modelos de machine learning. O cross-validation é uma forma simples, porém efetiva de avaliarmos o desempenho dos nossos modelos. Já o data leakage é um problema gravíssimo que se não prevenido da maneira correta, pode acabar com o desempenho do modelo quando o mesmo for colocar em produção.
Espero que esse post tenha te ajudado a compreender melhor ambos os conceitos e que seja útil da próxima vez que você for treinar um modelo. Como sempre, sugiro dar uma olhada nas referência que utilizei para criar esse post.
Referências
[1] Cross-validation: evaluating estimator performance. Link
Deixe um comentário