
O que é Machine Learning?
Atualmente, junto com data science, o termo machine learning está na moda. Por conta disso, esse termo aparece nos mais diversos lugares, inclusive matérias de jornais. No português brasileiro, ele costuma ser traduzido como aprendizado de máquina. Mas você já se perguntou o que é machine learning? Qual a diferença para inteligência artificial, que é outro termo muito popular? E Deep Learning (ou aprendizado profundo), o que é isso? Bom, vamos responder essas perguntas aqui.
Primeiramente, gostaria de salientar que este termo já vem sendo utilizado desde a década de 50/60. Ele se tornou mais popular nos últimos 10 anos porque o poder computacional aumentou tanto que diversos problemas difíceis, como classificar objetos em uma imagem, passaram a ser abordados utilizando a técnica. Mas o problema que começou a popularizar a técnica foi o filtro de spam para emails. Isso ocorreu em meados da década de 90. O diferencial, agora, é que problemas muito mais complexos, estão sendo “solucionados” e resultados notáveis estão sendo obtidos. Logo, rapidamente, o termo e seus algoritmos se tornaram uma tendência.
Paradigmas de aprendizado
As definipes de inteligência artificial, machine learning e deep learning possuem uma sobreposição. De maneira gera, podemos definir:
- Inteligência Artificial (IA): algoritmos que permitem o computador a imitar o comportamento humano.
- Machine Learning (ML): é uma maneira de alcançar o mesmo objetivo da IA; porém, os algoritmos aprendem a partir dos dados com uma mínima intervenção humana. É seguro dizer que ML é uma área de IA.
- Deep Learning (DL): é uma sub-área de ML na qual os modelos são compostos por redes neurais artificiais que possuem tantas camandas que são chamadas de profundas.
Segundo François Chollet, as diferenças entre os paradigmas de ML e IA podem ser ilustradas da seguinte maneira:
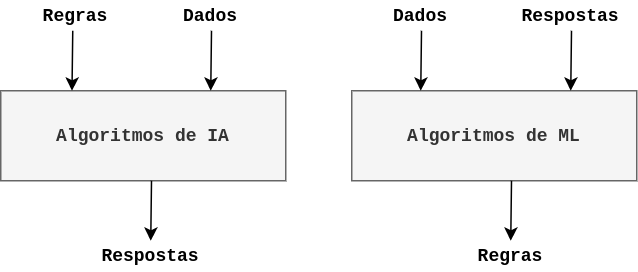
De maneira geral, enquanto IA é basedo em regras pré-estabelecidas para determinar as respostas, ML obtém as respostas para aprender as regras.
O que é Machine Learning?
Ok, entendi as diferenças de paradigma. Mas, o que de fato é um algoritmo de machine learning? Bom, existem algumas definições para essa técnica e vou tentar resumi-las com as minhas palavras. De maneira geral um algoritmo é considerado ser da área de machine learning se ele é designado para uma determinada tarefa sem utilizar instruções explícitas. O algoritmo se baseia em uma inferência para tomar uma decisão. Em outras palavras, o algoritmo aprende a solucionar um problema através de dados.
Tentando exemplificar, imagine que você queira desenvolver um algoritmo para detectar uma pessoa em uma imagem. Sem utilizar machine learning, você vai ter que construir um algoritmo específico pra isso. Logo, você, ser humano, vai passar sua experiência para esse código. Você sabe que uma pessoa tem pernas, braços, cabeça, etc. Logo, você vai desenvolver um código capaz de detectar essas características na imagem e retornar se existe ou não uma pessoa. Agora, se você for utilizar algum algoritmo de machine learning você não vai passar essa experiência para diretamente para o código. Você vai codificar um conjunto de regras gerais que vai utilizar diversos exemplos para realizar a detecção. Logo, você vai ter que coletar centenas/milhares de fotos de pessoas e apresentar para esse algoritmo. A partir daí o algoritimo vai ser treinado para aprender a detectar a existência de uma pessoa na imagem. Esse treinamento leva em consideração alguma métrica de desempenho e se ele for bem sucedido, a deteção será boa. Caso contrário, ruim.
Portanto, você tem que ter em mente que é fundamental você ter dados disponíveis para utilizar a técnica. E você pode se perguntar: mas o quanto de dado é suficiente? Bom, essa pergunta é complexa e vamos tentar respondê-la ao longo do curso. Mas ML depende de dados. Se você não tem dados bons e suficientes, essa técnica pode não servir para você. Aliás, é comum engenheiro da área relatares quem a maior parte do tempo se passa preparando os dados ao invés de melhorando o algoritimo.
Vantagens e desvantagens
Existem vantagens e desvantagens ao utilizar algoritmos de ML. É sempre bom ter em mente que nem sempre essa técnica vai ser aplicável ou a melhor possível. As vezes, um método mais simples soluciona o problema. Nem tudo são flores. A seguir, listo três vantagens e desvantagens de ML.
Vantagens
- Os algoritmos de ML são algoritmo de propósito geral, ou seja, um mesmo algoritmo que detecta spam na sua caixa de e-mail, pode ser utilizado para classificar amostras de plantas. Isso é uma grande vantagem, uma vez que não é necessário programar o algoritmo de maneira explícita.
- Os algoritmos podem ser atualizados de maneira relativamente fácil. Por exemplo, e-mails que são spam são alterados diariamente. Com isso, é possível ensinar os novos padrões para o algoritmo e atualizá-lo.
- Problemas difíceis que não possuem uma solução fechada podem ser abordados de maneira mais fácil utilizando ML.
Desvantagens
- Dados, dados, e mais dados. Tudo depende de dados. Se o problema não permite uma coleta boa e estruturada, é muito difícil (ou impossível) utilizar ML.
- É comum ocorrer problemas de generalização ao utilizar ML. Em outras palavras, seu algoritmo funciona muito bem para os dados que você possui. Porém, quando vai para produção a performance é muito pior. Vamos abordar esse problema mais para frente no curso.
- Dependendo do problema, seu algoritmo pode levar um longo tempo e necessitar de muito recurso computacional para ser treinado. Principalmente quando se trata de deep learning.
Tipos de aprendizado
Como dito anteriormente, algoritmos de ML precisam ser treinados. Treinar nada mais é do que apresentar para o algoritmo vários exemplos até que ele aprenda, de acordo com uma métrica, a interpretar esses exemplos. Existem três tipos principais de aprendizado, são eles:
- Aprendizado supervisionado: ocorre quando algoritmos de ML são treinados com base de dados que possuem entradas e saídas bem definidos. Por exemplo, para classificar câncer de pele em uma imagem, é necessário ter a imagem (entrada) e o diagnóstico (saída).
- Aprendizado não supervisionado: algoritmos são treinados com base de dados que possuem apenas a entrada. Não existe sáida associada a ela. Por exemplo, se quisermos agrupar objetos de acordo com a forma, temos apenas a entrada, que é a forma do objeto.
- Aprendizado por reforço: algoritmos são treinados através da observação do ambiente, selecionando e executando ações, e obtendo recompensas ou punições. Basicamente, o algoritmo precisa aprender uma solução para o problema por ele mesmo. Essa técnica é muito utilizada em jogos, como desenvolvida pela OpenAI para jogar Dota 2.
É claro que existem outras formas de aprendizado, como o semi-supervisionado. Mas não vamos entrar neste tópico neste curso. Apenas saiba que existe.
Tipos de problemas
Algoritmos de ML podem lidar com os mais diversos tipos de problema. Lembre-se que flexibilidade é uma grande vantagem. Os principais que vamos abordar neste curso são:
-
Classificação de dados: como o próprio nome sugere, é um problema que dado uma entrada temos que atribuir um rótulo. Por exemplo, classificar lesões de pele em uma imagem. Eu já fiz um post sobre o assunto.
-
Clusterização: é parecido com a classificação, mas a principal diferença é que não existe rótulo. É o exemplo dado para aprendizado não supervisionado. A ideia é encontrar padrões que definim dadas entradas em um mesmo grupo. Também falei sobre ele neste post.
-
Regressão: são problemas nas quais temos entradas e saídas, mas as saídas são contínuas. Por exemplo, imagine que queremos definir o preço de uma casa baseado em diversos atributos. Este poder modelado como um problema de regressão.
-
Predição de séries temporais: como o nome sugere, visa prever dados futuros de uma série. Poder o exemplo mais comum que é prever o próximo valor de uma ação ou a demanda de energia de um país no mês seguinte.
Considerações finais
A ideia deste post foi dar uma noção geral do que é e para que serve ML. Existem diversos outros conceitos básicos relacionados a ML que pretendo discutir em um outro posto, como por exemplo, o que é o trade-off entre bias x variância. Então, te vejo no próximo post.
Deixe um comentário