
Introdução a Máquina Restrita de mann (RBM)
Introdução
Neste post vamos discutir um pouco sobre a Máquina Restrita de mann (em inglês: Restricted mann Machine, RBM) [1,2]. A RBM ganhou destaque na primeira década dos anos 2000. Ela foi muito utilizada para compor camadas de redes neurais profundas (em inglês: Deep Neural Networks, DNNs) ou também conhecidas como redes de crenças profundas (em inglês:Deep Belief Networks, DBN). Esses tipos de redes possuem diversas camadas de neurônios para extração de características e por isso recebem o nome de redes profundas. Em um passado não muito distante elas quase não eram utilizadas pois era extremamente difícil treiná-las. Os algoritmos não eram eficazes e nem eficientes, tomando um longo tempo computacional quando executados. Algo que pode ser considerado um marco para o treinamento das redes profundas foi o desenvolvimento do algoritmo divergência contrastiva (do inglês: contrastive divergence, CD), proposto por Geoffrey Hinton (2006) para treinamento de RBM’s de forma gulosa. Ao longo do post chegaremos nele e vamos discutir o porque dele ser esse marco. Antes de continuar, se você se sentiu perdido com os termos utilizados até então, sugiro que leia nosso post sobre redes neurais. Além disso, a fundamentação teórica de uma RBM exige um bom nível de conhecimento em probabilidade e estatística, então não se assuste a primeira vista.
Modelagem da RBM
Bom, iniciando a parte teórica, a máquina de mann restrita [1,2] é, basicamente, uma rede estocástica constituída por duas camadas: uma visível e outra oculta. A camada de unidades visíveis representam os dados observados e está conectada à camada oculta, que por sua vez, deverá aprender a extrair características desses dados. Originalmente, a RBM foi desenvolvida para dados binários, tanto na camada visível quanto na camada oculta. Essa abordagem é conhecida como Bernoulli-Bernoulli RBM (BBRBM). Devido ao fato de existir problemas onde é necessário processar outros tipos de dados, [3] propuseram a Gaussian-Bernoulli RBM (GBRBM), que utiliza uma distribuição normal para modelar os neurônios da camada visível. Neste post, serão descritos os conceitos básicos referentes a abordagem GBRBM.
Na RBM as conexões entre neurônios são bidirecionais e simétricas. Isso significa que existe tráfego de informação em ambos os sentidos da rede. Além disso, para simplificar procedimentos de inferência, neurônios de uma mesma camada não estão conectados entre si. Sendo assim, só existe conexão entre neurônios de camadas diferentes, por isso a máquina é restrita. Na Figura 1 é mostrado uma RBM com \(m\) neurônios na camada visível (\(v_{1},\cdots,v_{m}\)), \(n\) neurônios na camada oculta (\(h_{1},\cdots,h_{n}\)), sendo (\(a_1,\cdots, a_m\)) e (\(b_1,\cdots, b_n\)) os vetores de bias e por fim \(\mathbf{W}\) a matriz de pesos das conexões. Daqui até o fim deste post, o conjunto \(\{\mathbf{W}, \mathbf{a}, \mathbf{b}\}\) será denominado \(\boldsymbol{\theta}\).
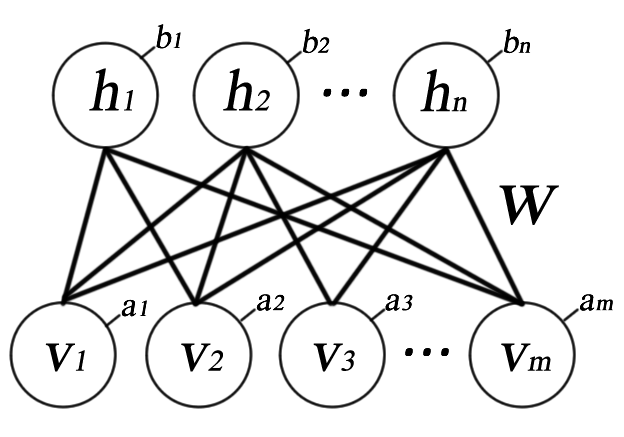
A RBM é um modelo probabilística baseada em energia, isso significa que a distribuição de probabilidade conjunta da configuração \((v,h)\) é obtida pela seguinte equação :
\[p(\mathbf{v},\mathbf{h}; \boldsymbol{\theta}) = \dfrac{e^{-E(\mathbf{v},\mathbf{h}; \boldsymbol{\theta})}}{\sum_{\mathbf{v},\mathbf{h}}e^{-E(\mathbf{v},\mathbf{h}; \boldsymbol{\theta})}} \tag{1}\]Sendo a função de energia descrita por:
\[E(\mathbf{v},\mathbf{h}; \boldsymbol{\theta}) = -\sum_{i=1}^{m} \frac{(v_{i}-a_{i})^2}{2\sigma_i^2} - \sum_{j=1}^{n}b_{j}h_{j} - \sum_{i,j=1}^{m,n} \frac{v_{i}}{\sigma^2} h_{j}w_{ij} \tag{2}\]A probabilidade que a rede atribui a um vetor visível, \(\mathbf{v}\), é dada pela soma de todas as probabilidades dos vetores escondidos \(\mathbf{h}$ (marginalização de \) \mathbf{v} $$), calculados por:</p>
\[p(\mathbf{v}; \boldsymbol{\theta}) = \dfrac{\sum_{\mathbf{h}} e^{-E(\mathbf{v},\mathbf{h} ; \boldsymbol{\theta})}}{\sum_{\mathbf{v},\mathbf{h}}e^{-E(\mathbf{v},\mathbf{h}; \boldsymbol{\theta})}} \tag{3}\]Como a RBM é restrita, ou seja, não possui conexões de neurônios entre uma mesma camada, as distribuições de probabilidade de \(\mathbf{h}\) dado \(\mathbf{v}\) e de \(\mathbf{v}\) dado \(\mathbf{h}\) são descritas pelas seguintes equações:
\[p(\mathbf{h}|\mathbf{v}; \boldsymbol{\theta}) = \prod_{j} p(h_{j}|\mathbf{v}) \tag{4}\] \[p(\mathbf{v}|\mathbf{h} ; \boldsymbol{\theta}) = \prod_{i} p(v_{i}|\mathbf{h}) \tag{5}\]Baseado na versão GBRBM [3], no qual a camada visível é contínua e a oculta binária, as distribuições condicionais são descritas pelas equações:
\[p(h_{j}=1|\mathbf{v} ; \boldsymbol{\theta}) = \phi (b_{j}+\sum_{i=1}^{m} v_{i}w_{ij}) \tag{6}\] \[p(v_{i}=v|\mathbf{h} ; \boldsymbol{\theta}) = N (v | a_{i}+ \sum_{j=1}^{n} h_{j}w_{ij},\sigma^{2}) \tag{7}\]Na qual \(\phi (x) = \frac{1}{1+e^{-x}}\), a função logística, e \(N\) é uma distribuição de probabilidade normal, com média \(v\) e desvio padrão \(\sigma^2\), normalmente utilizado como 1.
Treinamento de uma RBM
Basicamente, o objetivo do treinamento da RBM é estimar \(\boldsymbol{\theta}\) que faça com que a energia da rede diminua [4]. Como \(p(\mathbf{v}; \boldsymbol{\theta})\) é a distribuição dos dados de entrada, \(\boldsymbol{\theta}\) pode ser estimado a partir da maximização de \(p(\mathbf{v},\boldsymbol{\theta})\) ou, de maneira equivalente, \(\log p(\mathbf{v},\boldsymbol{\theta})\). Sendo assim, o gradiente descendente de \(\log p(\mathbf{v},\boldsymbol{\theta})\), com respeito a \(\boldsymbol{\theta}\) é calculado por:
\[\frac{\partial p(\mathbf{v},\boldsymbol{\theta})}{\partial \boldsymbol{\theta}} = \left \langle v_i h_j \right \rangle_d - \left \langle v_i h_j \right \rangle_m \tag{7}\]Na qual as componentes \(\left \langle v_i h_j \right \rangle_{d}\) e \(\left \langle v_i h_j \right \rangle_{m}\) são usadas para denotar as expectativas computadas sob os dados e o modelo, respectivamente.
A estimativa de \(\left \langle v_i h_j \right \rangle_{d}\) é obtida de maneira simples através das probabilidades condicionais \(p(h_{j}=1 \mid \mathbf{v} ; \boldsymbol{\theta})\) e \(p(v_{i}=v \mid \mathbf{h} ; \boldsymbol{\theta})\). Todavia, obter uma estimativa de \(\left \langle v_i h_j \right \rangle_{m}\) é muito mais difícil. Isso pode ser feito por meio do amostrador de Gibbs utilizando dados aleatórios alimentando a camada visível. Todavia, esse procedimento pode consumir um longo tempo para obter um resultado adequado. Felizmente, um procedimento mais rápido, denominado contrastive divergence (CD), foi proposto por [2] cuja ideia é alimentar a camada visível com dados de treinamento e executar o amostrador de Gibbs apenas uma vez, como ilustrado na Figura 2. Esta etapa foi denominada por [2] como reconstrução.
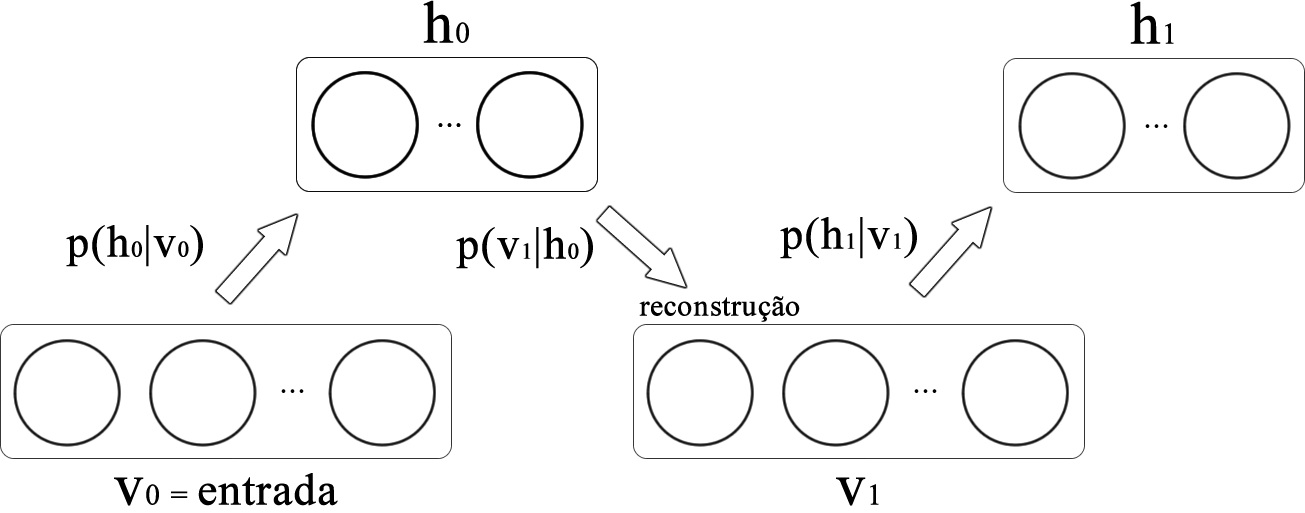
Para aplicar o algoritmo CD, o primeiro passo é igualar a camada visível \(\mathbf{v_0}\) aos dados de entradas e, logo após, estimar a camada oculta \(\mathbf{h_0}\) por meio da probabilidade condicional \(p(h_{j}=1 \mid \mathbf{v} ; \boldsymbol{\theta})\). Com isso, \(\left \langle \mathbf{v} \mathbf{h^{T}} \right \rangle_{d} = \mathbf{v_0}\mathbf{h_0^{T}}\). Em seguida, a partir de \(\mathbf{h_0}\), deve-se estimar \(\mathbf{v_1}\) por meio da probabilidade condicional \(p(v_{i}=v \mid \mathbf{h} ; \boldsymbol{\theta})\). De maneira similar, a partir de \(\mathbf{v_1}\), estima-se \(\mathbf{h_1}\), novamente por \(p(h_{j}=1 \mid \mathbf{v} ; \boldsymbol{\theta})\). Com isso, \(\left \langle \mathbf{v} \mathbf{h^{T}} \right \rangle_{m} = \mathbf{v_1}\mathbf{h_1^{T}}\). Por fim, o conjunto de parâmetros \(\boldsymbol{\theta}\) são atualizados da seguinte forma:
\[\mathbf{W^{t+1}} = \mathbf{W^{t}} + \Delta \mathbf{W^{t}} \\ \rightarrow \Delta \mathbf{W^{t}} = {\eta} (\mathbf{v_0}\mathbf{h_0^T} - \mathbf{v_1}\mathbf{h_1^T}) - {\rho} \mathbf{W^{t}} + {\alpha} \Delta \mathbf{W^{t-1}} \tag{8}\] \[\mathbf{a^{t+1}} = \mathbf{a^{t}} + \Delta \mathbf{a^{t}} \rightarrow \Delta \mathbf{a^{t}} = {\eta} (\mathbf{v_{0}} - \mathbf{v_{1}}) + {\alpha} \Delta \mathbf{a^{t-1}} \tag{9}\] \[\mathbf{b^{t+1}} = \mathbf{b^{t}} + \Delta \mathbf{b^{t}} \rightarrow \Delta \mathbf{b^{t}} = {\eta} (\mathbf{h_{0}} - \mathbf{h_{1}}) + {\alpha} \Delta \mathbf{b^{t-1}} \tag{10}\]Sendo que \(\{ \mathbf{W}, \mathbf{a}, \mathbf{b} \}\) são inicializados de maneira aleatória. Um passo a passo do algoritmo CD é apresentado a seguir:
- Inicialização:
- Preparar conjunto de dados de entrada;
- Informar número de neurônios para camada oculta \(\mathbf{h}\);
- \(\eta, \rho\) e \(\alpha\);
- Inicializar os parametros em \(\boldsymbol{\theta}\) de maneira aleatória;
- Repetir até que um número pré-determinado de iterações ou erro mínimo:
- Igualar a camada visível \(\mathbf{v}_0\) aos dados de entrada;
- Estimar a camada oculta \(\mathbf{h}_0\) por meio da probabilidade condicional \(p(\mathbf{h} \mid \mathbf{v})\);
- Estimar, a partir de \(\mathbf{h}_0\), a camada visível \(\mathbf{v}_1\) por meio da equação $$ p(\mathbf{v} \mid \mathbf{h});
- Estimar, a partir de \(\mathbf{v}_1\), a camada oculta \(\mathbf{h}_1\) por meio da equação \(p(\mathbf{h} \mid \mathbf{v})\);
- Atualizar \(\boldsymbol{\theta}\) utilizando as equações 8, 9 e 10;
- Retornar \(\boldsymbol{\theta}\) treinados
Os hiperparâmetros \(\eta, \rho\) e \(\alpha\) são conhecidos como taxa de aprendizado, fator de decaimento e momentum. G. Hinton [4] sugere \(\eta = 0.01$, \rho = [0.01, 0.0001]\) e \({\alpha} = 0.5\) para iteração menor do que 5 e \(\alpha = 0.9\) para as demais.
Implementação em Python
Deixo o meu repositório com uma implmentação da RBM em Python e TensorFlow (1.x). Nele é possível entender melhor toda a parte terórica explicada neste post. Você pode acessar o código clicando aqui.
Considerações finais
Esse post descreveu os conceitos básicos de uma RBMs. Como já disse, existem variações e melhorias neste algoritmo original. Como devem ter percebido, o entendimento de todo processo demanda um conhecimento mais avançado. Eu mesmo demorei um tempo considerável para entender todo esse processo. Caso esteja muito confuso, dê uma olhada no código também. Isso ajuda a entender os passos.
Referências
[1] Smolensky, P. Information processing in dynamical systems: Foundations of harmony theory. DTIC Document, 1986.
[2] Hinton, G. E. Training products of experts by minimizing contrastive divergence. Neural Computation, v. 14, n. 8, p. 1771–1800, 2002.
[3] Hinton, G. E.; Salakhutdinov, R. R. Reducing the dimensionality of data with neural networks. Science, v. 313, n. 5786, p. 504–507, 2006.
[4] Hinton, G. A practical guide to training restricted mann machines. Momentum, v. 9, n. 1, p. 926, 2010.
Deixe um comentário