
Introdução ao Scikit-learn - Parte 1: uma visão geral
Introdução
Se você chegou até este post então você provavelmente já sabe que a Scikit-learn é uma biblioteca open source de machine learning para Python. Atualmente, é seguro dizer, que ela é maior e mais utilizada na área. Existem vários motivos para isso, listando alguns:
- Utilização fácil, intuitiva e replicável
- Documentação excelente
- Fácil integração com outros pacotes do Python como Pandas, Matplotlib, Numpy, etc
- Manutenção em dia
- Código aberto com licença BSD
- etc
Dado a sua importância e relevância, nada mais justo do que termos uma série de posts neste blog para introduzir o uso da biblioteca. A ideia inicial é apresentar o conteúdo em 5 partes e de maneira bem mão na massa.
Info: a segunda parte do tutorial Parte 2: criando o primeiro projeto está disponível neste link
Os conceitos e informações disponíveis nesta série são retirados da documentação oficial da biblioteca e do livro Hands-On Machine Learning with Scikit-Learn.
Outro ponto relevante é que eu já espero que você entenda os conceitos básicos de machine learning e saiba o básico de programação em Python para de fato entender o que a biblioteca faz. Você deve saber o mínimo sobre NumPy e Matplotlib. Por isso, listo alguns posts relevantes deste blog que acredito que você deveria dar uma olhada caso não tenha domínio no assunto:
- Curso de Python
- O que é Machine Learning?
- Classificação de dados
- Medida de desempenho de classificadores
- O problema de otimização
Por fim, antes de iniciar, todos os códigos exemplificados nessa série estão disponíveis neste repositório do Github. Nele, você encontra informações sobre instalação, dependências, etc. Agora, sem mais delongas, vamos iniciar o payload da nossa série!
Info: o repositório no Github contém um série de notebooks implementando os códigos utilizados nessa série. Se você curtiu considere deixar a sua estrelinha no repositório. Isso me ajuda a saber se foi útil ou não.
Visão geral da biblioteca
Seguindo a documentação da oficial da biblioteca, para termos uma visão geral da mesma, podemos dividí-la em cinco módulos:
- Estimadores básicos
- Pre-processamento e transformadores
- Avaliação de modelos
- Pipelines
- Busca automática de parâmetros
Na sequência, vamos discutir a função de cada um dos módulos.
Estimadores básicos
A Scikit-learn possui vários algoritmos e modelos de machine learning. Na biblioteca eles são nomeados de estimadores (estimators). Um estimador pode ser, por exemplo, uma rede neural artificial que executar uma classificação de dados. O que é legal na biblioteca é que os estimadores, não importa o algoritmo (rede neural, KNN, árvore de decisão, etc), segue um mesmo padrão utilização que vai incluir uma função para treinamento chamada fit() e para realizar predições, a predict().
Vamos utilizar como exemplo uma rede neural para realizar classificação. Na biblioteca ela é chamada de MLP (multilayer perceptron) e fica dentro do sub pacote de neural_network. Para utilizá-la, basta fazer:
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
Em resumo, criamos um objeto da classe MLPClassifier utilizando todos os parâmetros como default. Não se preocupe com isso agora, vamos abordar isso mais para frente. A intenção aqui é ter uma visão geral. Existem vários métodos e atributos relacionados ao objeto mlp. Mas desejamos explorar aqui apenas o fit() e o predict().
O fit() é utilizado para treinar o nosso modelo, que neste caso é a rede neural. Como nesse caso vamos lidar com um problema de classificação de dados e ele é um problema de aprendizado supervisionado, precisamos de dados de um conjunto de entradas e saídas para treinar o classificador. Na sklearn o conjunto de entradas é representado por uma matriz, que vamos chamar de X, na qual cada linha representa uma amostra e cada coluna um atributo do problema em questão. Por sua vez, um array y vai possuir suas respectivas saídas. A função fit(), neste caso, recebe X e y como entradas para o treinamento do modelo. Tanto X quanto y precisam ser array-like na qual os dois tipos mais comuns são list ou numpy.array.
X = [[1, 2, 3, 4], # Entrada com 3 amostras de 4 atributos
[4, 5, 6, 7],
[7, 8, 9, 8]]
y = [0, 1, 1] # Uma saída para cada amostra
mlp.fit(X, y)
Após rodar o fit() o modelo estará treinado (se o treinamento foi bom ou não, isso será tema para as próximas partes). Para efeturar uma predição, devemos chamar o método predict() utilizando uma entrada com o mesmo número de atributos das amostras alocadas em X (neste exemplo, 4). Obviamente, o método retorna uma predição para cada entrada.
X_teste = [[1, 6, 3, 1], # Teste com 2 amostras
[4, 2, 4, 9]]
y_pred = mlp.predict(X_teste) # y_pred será um array com duas predições, ex: [1, 0]
Cada tipo de modelo implementado na sklearn tem seus próprios algoritmos treinamento, seus parâmetros de configuração, etc. Porém, a maneira de usar a biblioteca segue sempre o mesmo padrão.
Pré-processamento e transformadores
Como já vimos em vários posts deste blog, sempre que vamos treinar um modelo de predição é quase que obrigatório normalizarmos os dados de entrada. Essa parte da biblioteca visa atacar justamente essa tarefa. O interessante é que os algoritmos de pré-processamento da biblioteca seguem o mesmo padrão dos estimadores possuindo um método fit() e um transform() (ao invés de predict()).
Existem diversos transformadores para pré-processar os dados na biblioteca. Você os encontra dentro do subpacote sklearn.preprocessing. Nesta seção, vamos exemplificar com um bem simples, que é normalizar os dados entre 1 e 0 dividindo eles pelo máximo de cada atributo. Dentro la biblioteca ele esse método se chama MaxAbsScaler. A estrutura do código é basicamente a mesma da seção anterior.
from sklearn.preprocessing import MaxAbsScaler
normalizador = MaxAbsScaler()
X = [[1, 2, 3, 4], # Entrada com 3 amostras de 4 atributos
[4, 5, 6, 7],
[7, 8, 9, 8]]
normalizador.fit(X) # Calcula o max de cada atributo
X_teste = [[1, 6, 3, 1],
[4, 2, 4, 9]]
X_teste_norm = normalizador.transform(X_teste) # normaliza X_teste de acordo com X
No caso dos pré-processadores, o método fit() apenas obtem os dados necessários para aplicar a transformação. Nesse caso, ele calcula o máximo de cada atributo (ou seja, de cada coluna). Por sua vez, o transform() aplica a normalização para dados novos. No caso desse método, apenas divide pelo máximo para colocar todos os atributos entre 0 e 1.
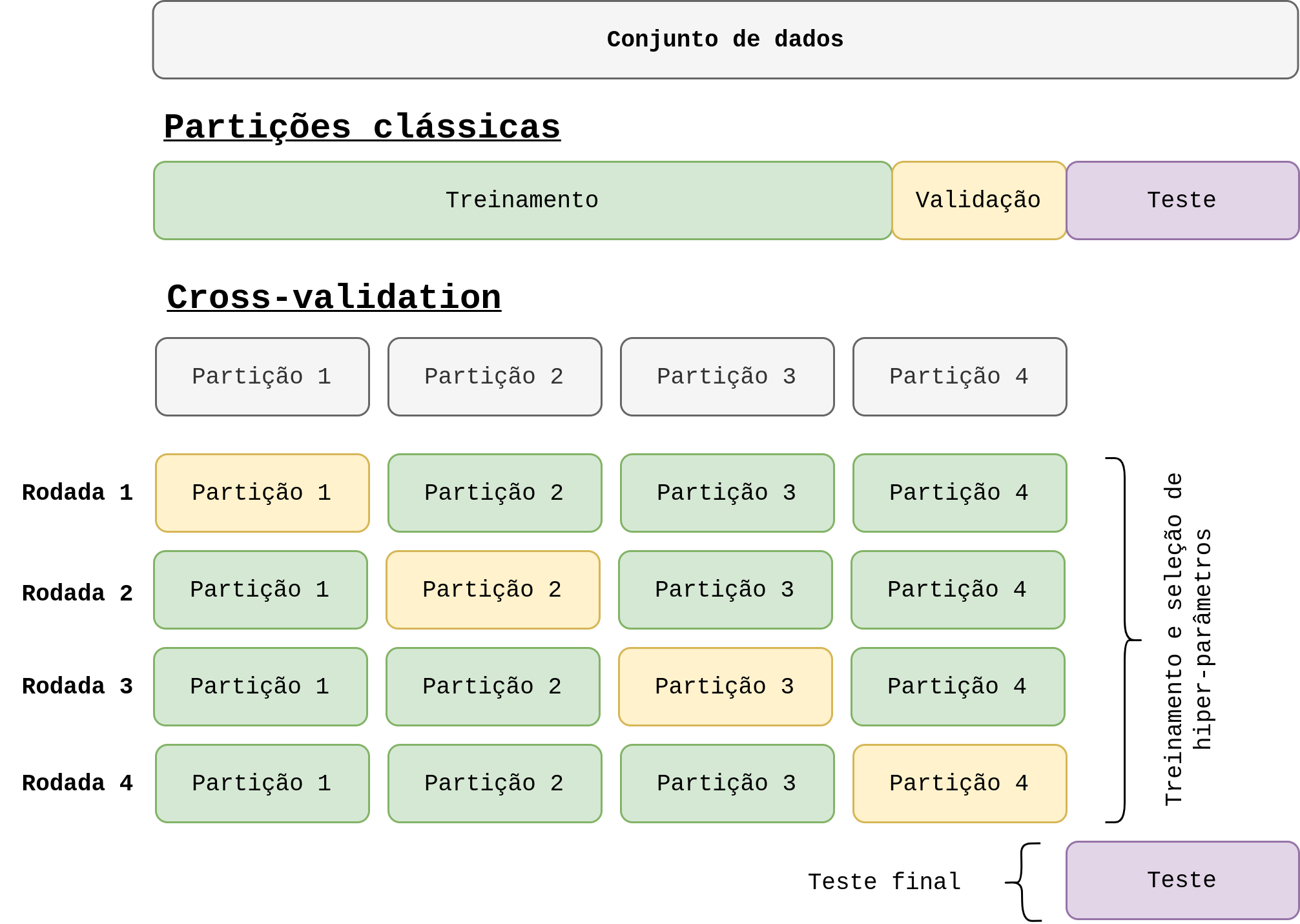
Avaliação de modelos
Tão fundamental quanto treinar um modelo é avaliar a qualidade do treinamento e o desempenho do mesmo. A sklearn oferece diversas ferramentas para avaliar modelos de machine learning. Dois subpacotes extremamente úteis são o sklearn.model_selection e sklearn.metrics. Eles possuem funções para auxiliar (helpers) na construção dos nossos modelos, como por exemplo:
Existem diversas funções muito úteis como pro exemplo:
sklearn.model_selection.train_test_split: divide os dados em partições de teste e treinosklearn.model_selection.KFold: criaKpartições utilizando validação cruzada (cross validation)sklearn.metrics.accuracy_score: calcula a acurácia de um classificadorsklearn.metrics.auc: calcula a área sob a cuva a partir de uma curva ROCsklearn.metrics.balanced_accuracy_score: calcula a acurácia balanceada de um classificador
De maneira rápida, apenas para exemplificar o uso de uma dessas funções auxiliares, ainda considerando nosso classificador, imagine que obtivemos um conjunto de predições y_pred através da função predict(). O conjunto com os labels verdadeiros (ground truth) está armazenado em y. Para calcularmos a acurácia e acurácia balanceadaé simples e rápido:
from sklearn.metrics import accuracy_score, balanced_accuracy_score
y = [1, 0, 1, 0]
y_pred = [0, 0, 1, 0]
print(f"Acuracia: {accuracy_score(y, y_pred)}")
print(f"Acurácia balanceada: {balanced_accuracy_score(y, y_pred)}")
Pipelines
Como você deve ter percebido cada uma das seções anteriores envolve um passo (basicamente obrigatório) para treinarmos um modelo de machine learning. A sklearn oferece uma maneira de criarmos um pipeline para juntarmos alguns desses passos em apenas uma chamada de função. Para isso, temos que utilizar o subpacote sklearn.pipeline. Continuando no nosso exemplo de classificação de dados, imagine que já temos os dados de entrada X e saída y. A nossa intenção é basicamente:
- dividir os dados em partições de treino e teste
- normalizar os dados
- treinar nossa MLP
- calcular a acurácia e a acurácia balanceada.
Para isso, podemos fazer:
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import MaxAbsScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, balanced_accuracy_score
from sklearn.model_selection import train_test_split
X = [[1, 2, 3, 4],
[4, 5, 6, 7],
[7, 8, 9, 8],
[1, 5, 7, 9]]
y = [0, 1, 1, 0]
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, random_state=0)
meu_pipeline = Pipeline(steps=[
("normalizacao", MaxAbsScaler()),
("MLP", MLPClassifier())
])
meu_pipeline.fit(X_treino, y_treino)
y_pred = meu_pipeline.predict(X_teste)
print(f"Acuracia: {accuracy_score(y_teste, y_pred)}")
print(f"Acurácia balanceada: {balanced_accuracy_score(y_teste, y_pred)}")
Observe que o algoritmo de normalização e o modelo foram empacotados na mesma estrutura, chamada de pipeline dentro da sklearn. Dessa forma, sempre a instância meu_pipeline for chamada, ela vai executar todos os passos descritos nela. Dois pontos importantes a se observar: 1) passamos sempre uma instância da classe para o pipeline, ou seja, MaxAbsScaler() (precisa dos parenteses); 2) o pipeline é executado em sequência, ou seja, primeiro a normalização e depois o modelo.
Obviamente, você poderia rodar esse modelo instanciando cada parte separadamente e chamando cada método separadamente (ainda mais neste caso que é apenas um exemplo simples). Porém, essa abordagem é bastante útil quando as coisas começarem a crescer e para fazermos busca de parâmetros, que é o tema da próxima seção.
Busca automática de parâmetros
Todo modelo de machine learning possui parâmetros (conhecido como hiper-parâmetros) que precisa ser definido antes do treinamento. Determinar quais são os melhores parâmetros não é algo tão fácil. Mas sabemos que tais parâmetros é muito importante para generalização e qualidade do modelo. Normalmente a escolha dos melhores parâmetros é feita de maneira empírica. Para facilitar tal busca, a sklearn oferece algumas ferramentas para busca automática de parâmetros. Os dois métodos mais comuns são o GridSearchCV() e o RandomizedSearchCV(). A ideia de ambos é parecida: buscar o melhor conjunto de parâmetros para um estimador utilizando cross-validation. Porém, o primeiro faz um busca exaustiva de acordo com uma lista de parâmetros especificados e o segundo faz a mesma busca mas amostrando os valores dos parâmetros através de uma distribuição informada.
A estrutura de ambos é basicamente a mesma. Obviamente, é necessário conhecer mais a fundo as configurações do modelo que deseja buscar os parâmetros. Utilizando o pipeline criado na seção anterior, um parâmetro da MLP que temos que determinar é a taxa de aprendizado (learning rate). Até o momento, deixamos ela como valor default (learning_rate_init=0.001). Mas podemos realizar uma busca da mesma da seguinte forma:
(...)
# Determinando os parametros a ser testados
from sklearn.model_selection import GridSearchCV
param_busca={
'MLP__learning_rate_init': [0.1, 0.01, 0.001]
}
buscador = GridSearchCV(estimator=meu_pipeline, param_grid=param_busca, cv=2)
buscador.fit(X, y)# realizando a busca
print("Melhor LR:", buscador.best_params_)
print("Score:", buscador.score)
De maneira geral, o que precisamos fazer é definir um dicionário com os parâmetros que queremos buscar (pode ser um ou vários). Nesse passo é importante garantir que a chave do dicionário seja exatamente igual ao parâmetro existente no estimador/modelo. E na sequência passar o estimador e o dicionário para o buscador. Perceba que o buscador também tem o método fit(), que o padrão da da biblioteca para iniciar o método. Observe também que neste caso passamos o pipeline meu_pipeline criado na seção anterior. Aqui vai uma informação importante: você poderia usar o GridSearchCV() sem criar o pipeline, ou seja, criando o modelo, depois normalizando os dados separadamente; Porém, na documentação da biblioteca eles afirmam que utilizar o pipeline é uma opção mais adequada para evitar vazamento de dados entre as partições de treino e teste.
Info: para mais informações sobre vazemento de dados acesse o nosso post Avaliação de modelos, cross-validation e data leakage.
Considerações finais
A sklearn em si é uma biblioteca enorme. A intenção desse post é passar uma visão geral dos principais componentes da mesma. Nas próximas partes dessa série de posts, aprofundar um pouco mais sobre as principais partes da biblioteca. Porém, ainda assim, será apenas um recorte. Muitas coisas vão, inevitávelmente, ficar de fora. Por conta disso, é importante ter em mente que a documentação é a sua melhor amiga. Acredito que nem os criadores da biblioteca conseguem saber de cabeça tudo que ela oferece. Por conta disso a documentação é tão importante. E o fato dela ser extremamente bem feita, é o um dos motivos da sklearn ser tão relevante na área.
Lembre-se que o Jupyter notebook resumindo esse post está disponível neste link.
Deixe um comentário